
An open scientific seminar of the Institute of Informatics and Quantitative Economics on automatic quality assessment of articles in multilingual Wikipedia and identification of important sources of its information on various topics was held at the Poznań University of Economics and Business. During the seminar, Dr. Włodzimierz Lewoniewski discussed the methods and tools used to analyze and evaluate content in a popular multilingual encyclopedia and ways of identifying and assessing information sources.
Wikipedia, as the largest and most popular open-access online encyclopedia, plays an important role in global access to knowledge and information. This platform offers quick access to a huge amount of information on almost any topic, making it a valuable resource for students, teachers and researchers. Wikipedia enables equal access to information for people from different backgrounds and regions of the world, contributing to blurring the differences in access to knowledge. Currently, it has over 62 million articles in over 300 languages.
Wikipedia’s freedom to edit is both its great asset and its challenge. While the freedom to add and modify articles in this encyclopedia enables the democratization of access to knowledge and supports global cooperation, it also requires effective quality control and moderation mechanisms. The freedom to edit Wikipedia allows everyone, regardless of education level or social position, to contribute to building and developing a publicly available body of knowledge. This allows for broad access to creating and sharing information. Compared to traditional encyclopedias, Wikipedia can be updated almost immediately when new information or events appear. However, it should also be taken into account that this freedom to edit Wikipedia may lead to the intentional introduction of false information, removal of valuable content or other forms of vandalism, which undermines the credibility and quality of the encyclopedia. Furthermore, different viewpoints and beliefs of editors may lead to bias in articles, which may affect the neutrality and objectivity of the information presented. Additionally, frequent editing and revisions can lead to excessive variability in some articles, making it difficult to maintain the consistency and quality of information. Therefore, ensuring high quality of all articles in different languages in the face of editing freedom is a significant challenge.
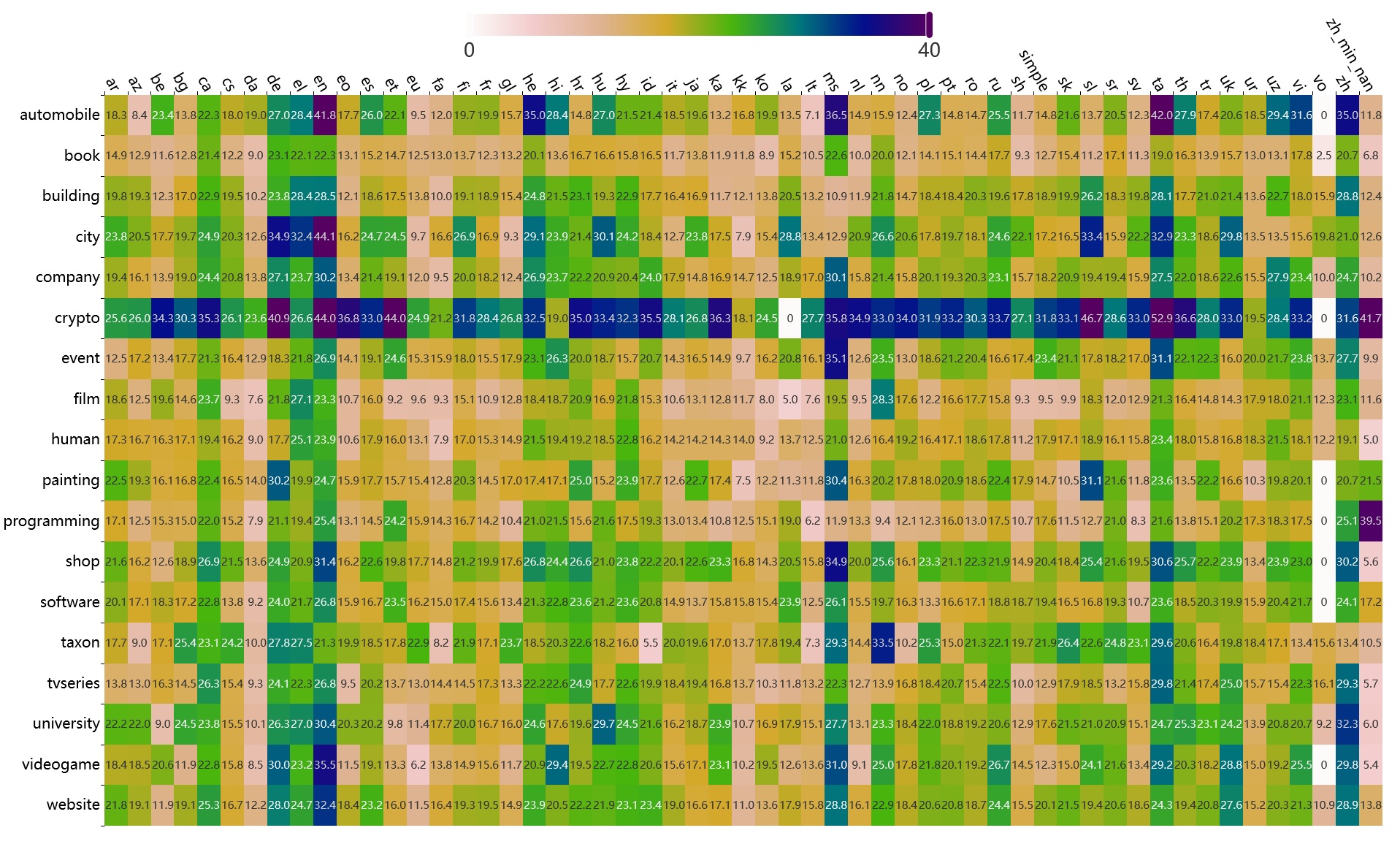
The Department of Information Systems conducts research in the area of creating models for automatic assessment of the quality of Wikipedia articles in various languages. Hundreds of measures have been developed as part of this research. Some of them have been implemented in the WikiRank tool, which allows for quality assessment using a synthetic quality measure on a continuous scale from 0 to 100. The figure below shows one of the charts presented during the seminar, which shows the average quality values of Wikipedia articles in different languages and topics using this measure (data as of February 2024, an interactive version of this chart is also available):
Scientific research also focuses on assessing the sources of information provided in Wikipedia articles. Currently, there are over 330 million references (footnotes) to sources in Wikipedia articles. Using various measures, it is possible to assess the importance of individual websites as sources of information. Some of the developed models have been implemented in the BestRef tool, which contains information on the ratings of millions of websites.
Wikipedia’s automatic article quality assessment aims to identify the extent to which individual articles meet certain quality criteria, such as completeness, neutrality, reliable sources, and style. This process is particularly important in the context of Wikipedia’s multilingualism, where linguistic and cultural diversity introduces additional challenges. Machine learning algorithms, including supervised and unsupervised classification, can be used to identify qualitative patterns in articles, based on previously labeled data.
Open semantic knowledge bases such as DBpedia and Wikidata may play a special role in the process of creating quality assessment models. These resources are important elements of the open data ecosystem and the semantic Internet. They enable organized and easy access to huge collections of knowledge. By structuring and semantically organizing data, DBpedia and Wikidata can be a valuable source for researchers and scientists. They enable advanced analyzes in many fields, from social sciences to linguistics to biology and medicine, opening new opportunities for scientific discoveries and innovations. Like Wikipedia, these projects support multilingual data processing, which is crucial for global access to knowledge.
It is worth mentioning that the better quality of Wikipedia may contribute to the improvement of other popular websites and tools. For example, Internet search engines (e.g. Google, Bing) use data from Wikipedia to enrich their search results through the so-called “knowledge boxes” that appear next to search results, providing short summaries and background information about the search terms or people. These summaries often draw content directly from Wikipedia, providing users with quick access to concise information. Another example – tools based on generative artificial intelligence (e.g. ChatGPT) use data from Wikipedia as part of their learning process. The knowledge gathered in Wikipedia helps in training models on a variety of data, which allows for the creation of more precise and content-rich generated materials.
The seminar of the Institute of Informatics and Quantitative Economics took place on February 16, 2024.